
Subword Modeling
在之前的学习中,我们都以有限的词汇作为基本假设来训练模型。在遇到“字典”里没出现过的词语时,我们通常将其标记为 “UNK”。但事实上,即便一个词不存在于字典中,我们也可以从它的结构推测出意思。类似英语中 er 结尾、ify 结尾的词,总带有某种特殊的涵义(表示人,表示“使……化”)。于是,我们可以以一个更小的尺度来分析单词——subword modeling。更极端一点地,我们可以从单个字符作为基本单位进行分析。而 subword 是在 word level 和 character level 之间的一个折衷。
The byte-pair encoding algorithm

Motivating word meaning and context
Old fashion, only the word embeddings are pretrained:
- Start with pretrained word embeddings. The same word just has the same embedding like in word2vec model.
- Learn how to incorporate context in an LSTM or Transformaer while training on the task.
Some issues for old fashion:
- The training data we have for our dowstream task must be sufficient to teach all contextual.
- Most of the parameters in our network are initialized randomly.
Modern NLP, all parts are pretrained jointly:
- All (almost) parameters in NLP networks are initialized via pretraining
- Pretraining methos hide the parts of the input from the model, and train the model to reconstruct those parts. (与 word2vec 类似。在 word2vec 训练中,我们的 center word 只有自己的信息,其窗口内的邻接词都被对它屏蔽掉,然后进行预测,根据结果进行惩罚等)
The modern fashion has been exceptionally effective at building strong:
- representation of language
- parameter initializations for strong NLP models
- Probability distributions over language that we can sample from
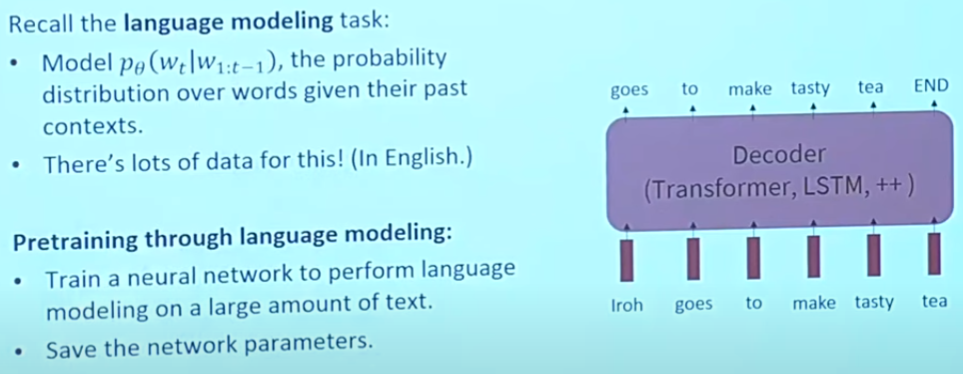
Pretraining through language modeling
The pretraining / Finetuning Paradigm
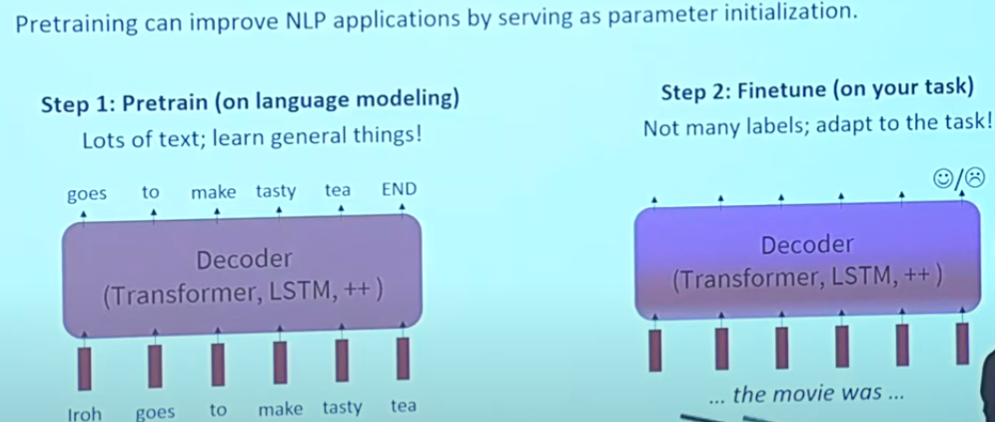
Stochastic gradient descent and pretrain / finetune

Pretraining decorders
Our objectives: language model to generate next word.
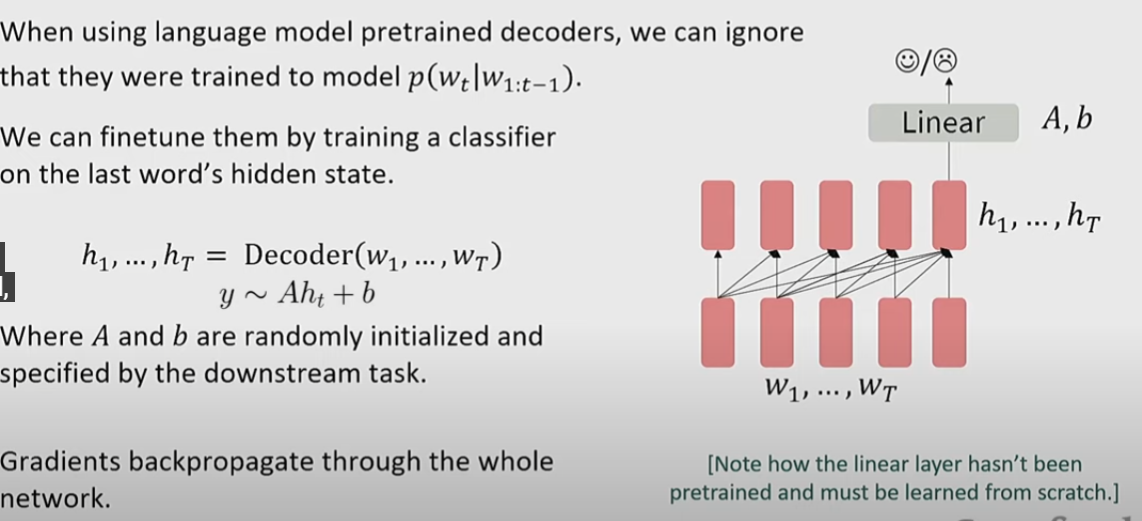
We don’t need to use it as a language model or probability distribution. We just use it to initialize the parameters.

There is no need to change architecture. Just with the same pretraining process and some format inputs, the model can adapt to various tasks.

Pretraining encoders: BERT
With bidirectional network, we can’t use formal language model. The model we use called masked language model.
With a given sentence, we take a fraction of them to mask, and predict them. We only have loss on the words which is masked.
In practice, to generalize the model further, we don’t just replace some words (or subwords) with mask token. We add more uncertainty.

Pretraining is expensive and impractical. Finetuning is practical and common on a single GPU.
Pretrain once, finetune many times
More BERT

Pretraining encoder-decorders
Doing language modeling on half the sequence.

What’s different from BERT is that we mask various lenth of spans and predict them.



Comments NOTHING