
标题中的解决打了引号,因为本文提供的思路只适用于某些情况。
起因
最近 huggingface 连接超时的情况越来越频繁,但之前也只要多试几次,开始下载了就没问题。然而今天需要从 datasets 加载一个 36 G 的数据集,重试了很久都没用。
思路
首先想到的是科学上网,然而这只对小文件有效。另外,不论是直接服务器上架代理,还是本地用代理下载完再上传服务器,都不太理想。考虑到未来很长一段时间内,huggingface 可能都无法访问,科学上网显然不是最好的方案(受限于速度、成本)。
然后想到改 hosts 文件,搜了下好像也不是很好用。
国内也没有比较完善的镜像,也找不到类似 github 加速的项目。最后我把目光放在 google colab 上。
解决方案
colab 的免费方案中,提供了 100 G 的硬盘(实际可用 80G),我最初的想法是在 colab 上下载完数据,再挂载 Google Drive(colab 侧原生支持,服务器侧用 CF 挂载) 或者 One Drive(两侧都用 python 库实现),将数据文件上传,再由服务器去下载回来。但两者都需要额外操作,也不方便。随后想到,这 36 G 的数据集中,我实际需要的只有 3 k 条,完全没必要传输整个数据集,直接在 colab 处理好,过滤出要的数据再下载即可。
然而,下载数据的环节又出了问题。因为 load_dataset 是先缓存所有文件,再去生成 split,导致实际硬盘空间需求超过了 80 G,根本加载不了。于是我又去找方法,想实现分片加载之类的效果。终于在 load_dataset 参数中找到一个 streming,它的作用是在加载数据时,不缓存所有文件,而是返回一个可迭代数据集对象,在迭代过程中逐个缓存当前所需文件,以节省空间。当然,这样做的缺点在于无法随机访问。但这对我来说我无关紧要。
效果
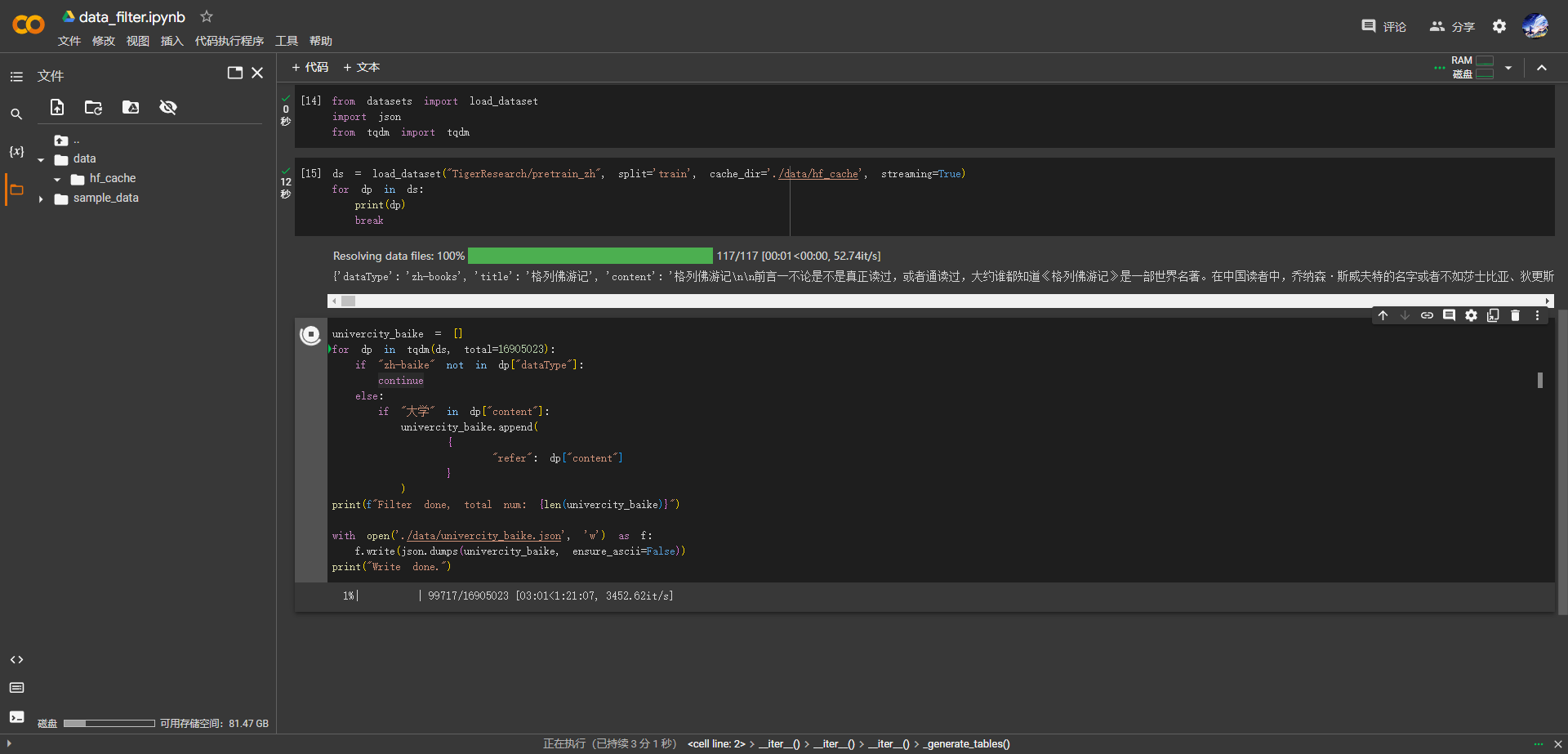
今后的数据清洗环节其实都可以直接在 colab 中完成了。
后续可以再研究下联动网盘,实现模型下载加速的效果。

Comments NOTHING