
原文:从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
预训练
概念
对于一类任务(e.g. 图像、语言),先使用有大量数据的任务做预训练,保存得到的网络参数。到具体任务时,加载之前保存的参数,再做训练。
加载预训练参数后的两种处理
- Frozen:底层网络参数固定不变
- Fine-Tuning:底层网络参数随训练进程不断更新
预训练的好处
- 面对数据量较少的具体任务时,使用预训练好的模型参数,加上具体任务的数据做 Fine-Tuning,能够解决数据不足的问题。
- 即便任务的数据足够,使用预训练模型也能加快训练的收敛速度。
预训练为什么有效?
简单来说,网络中越是底层的部分,所学习到的特征越是与具体任务无关,或者说越是”通用“。

以人脸识别任务为例,第一层(底层)的部分学习到一些线段、简单的图形特征;第二层学习到了五官的特征;第三层,学习到了人脸的轮廓。显然,底层的线段、简单的图形特征,是在所有图像任务中都可以通用的。而高层的参数,与具体任务的关联较大。所以,使用预训练模型时,我们往往使用其底层参数来初始化新模型的参数,而不使用高层参数。
Word Embedding
听说过word embedding吗?2003年出品,陈年技术,馥郁芳香。word embedding其实就是NLP里的早期预训练技术。
这其实就是大名鼎鼎的中文人称“神经网络语言模型”,英文小名NNLM的网络结构,用来做语言模型。这个工作有年头了,是个陈年老工作,是Bengio 在2003年发表在JMLR上的论文。它生于2003,火于2013,以后是否会不朽暂且不知,但是不幸的是出生后应该没有引起太大反响,沉寂十年终于时来运转沉冤得雪,在2013年又被NLP考古工作者从海底湿淋淋地捞出来了祭入神殿。为什么会发生这种技术奇遇记?你要想想2013年是什么年头,是深度学习开始渗透NLP领域的光辉时刻,万里长征第一步,而NNLM可以算是南昌起义第一枪。在深度学习火起来之前,极少有人用神经网络做NLP问题,如果你10年前坚持用神经网络做NLP,估计别人会认为你这人神经有问题。所谓红尘滚滚,谁也挡不住历史发展趋势的车轮,这就是个很好的例子。
- NNLM 的副产品——Word Embedding
- Word2Vec:CBOW 或 Skip-gram 方法
- Glove
使用 Word Embedding 其实就是使用预训练模型的参数初始化新模型的参数(词向量这一层)。同样的,也可以 Frozen 或 Fine-Tuning。
Word Embedding 最大的问题——无法区分多义词的不同语义。
ELMO
ELMO是“Embedding from Language Models”的简称,其实这个名字并没有反应它的本质思想,提出ELMO的论文题目:“Deep contextualized word representation”更能体现其精髓。
主要思想:虽然预训练得到的 Word Embedding 是静态的,但可以在使用时根据上下文对其做调整。
模型主要分为两个阶段:第一个阶段利用语言模型做预训练(双层 LSTM);第二个阶段从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。
具体细节见笔记。
每个人的学术审美口味不同,我个人一直比较赞赏要么简洁有效体现问题本质要么思想特别游离现有框架脑洞开得异常大的工作,所以ULFMiT我看论文的时候就感觉看着有点难受,觉得这工作没抓住重点而且特别麻烦,但是看ELMO论文感觉就赏心悦目,觉得思路特别清晰顺畅,看完暗暗点赞,心里说这样的文章获得NAACL2018最佳论文当之无愧,比ACL很多最佳论文也好得不是一点半点,这就是好工作带给一个有经验人士的一种在读论文时候就能产生的本能的感觉,也就是所谓的这道菜对上了食客的审美口味。
效果
ELMO 很好地解决了多义词的问题。在 Word Similarity 任务中,可以根据上下文的不同,区别出同一个词的不同的词义,甚至词性也能对应起来。
缺陷
使用了 LSTM 自慰特征提取器,而 LSTM 的特征提取能力远弱于 Transformer。
预训练方法:
- 以 ELMO 为代表的基于特征融合的方法
- GPT 开创的基于 Fine-Tuning 的模式
从 Word Embedding 到 GPT
Generative Pre-Training
也采用两阶段的模式,第一阶段是利用语言模型进行预训练,第二个阶段通过 Fine-Tuning 的模式解决下游任务。
预训练阶段其实与 ELMO 类似,但:特征抽取器使用 Transformer,而非 RNN;采用单向语言模型,而非双向。这里的“单向”指的是,语言模型的任务目标,是根据上文预测单词;而“双向”是根据上下文。
使用单向模型在现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的,白白丢掉了很多信息。
其次,我的判断是Transformer在未来会逐渐替代掉RNN成为主流的NLP工具,RNN一直受困于其并行计算能力,这是因为它本身结构的序列性依赖导致的,尽管很多人在试图通过修正RNN结构来修正这一点,但是我不看好这种模式,因为给马车换轮胎不如把它升级到汽车,这个道理很好懂,更何况目前汽车的雏形已经出现了,干嘛还要执着在换轮胎这个事情呢?
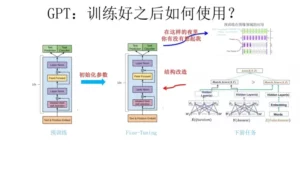
在第二阶段,具体任务的网络要向 GPT 的网络结构看齐,从而使用预训练参数进行初始化,并使用具体任务去训练(Fine-Tuning)。这十分类似前述的 CV 领域的预训练过程。
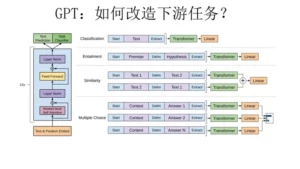
如上图所示,对于各类任务,只需要在输入部分进行改造即可。
缺陷方面,主要是没有使用双向的语言模型。
BERT
与 GPT 完全相同的两阶段模型。
但预训练阶段使用双向语言模型,且数据规模更大。
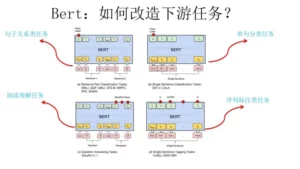
Fine-Tuning 阶段同样需要对下游任务网络结构进行改造,但与 GPT 不同。
NLP 四大类任务:
- 序列标注:分词/POS Tag/NER/语义标注
- 分类任务:文本分类/情感计算
- 句子关系判断:Entailment/QA/自然语言推理
- 生成式任务:机器翻译/文本摘要
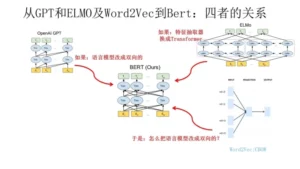
几个模型的关系
在使用 Transformer 做双向语言模型任务时,BERT 采用了类似 CBOW 的方案,挖掉待预测的词,并使用上下文去预测。
Masked LM
本质思想时 CBOW,但细节方面有些改进。
具体做法是,随机选择预料中 15%的单词,将其用 [Mask] 掩码代替,然后要求模型去预测这个单词。但是,为了避免在训练中让模型看到太多 [Mask],从而引导模型认为输出是针对 [Mask] 这个标记的,BERT 使这 15%的单词中,80% 被真正替换,10% 被替换为其他单词,10% 不做变动。
Next Sentence Prediction
BERT 要求模型除了做 Masked LM 外,还要附带做一个句子关系预测,从而判断生成的句子是否是上一句的后续。因为单词预测粒度的训练到不了句子这个层级,增加这个任务有助于下游句子关系判断任务。
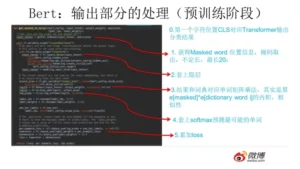
BERT 的输入和输出
模型的输入是线性序列,两个句子间有分隔符,起始和终止处有两个标识符。每个单词有三个 Embedding,分别是单词 Embedding(词向量)、位置 Embedding(单词顺序)、句子 Embedding(归属于哪个句子)。
输出部分参考:
效果

从上图的有效因子分析可以发现,双向语言模型起了最主要的作用(尤其是需要下文的任务),而 NSP 只对个别具体任务比较重要。
结语
五年过去,站在 2023 年来看,作者对 “Transformer 居 NLP 研究主导地位”的预言的确应验了。近几年这个领域的发展日新月异,需要学习的东西太多,能够真正用到的时间却太少。不过我相信,只要坚持学习,每天进步一点,总能有不小的积累。

Comments NOTHING