
在Transformer作为特征抽取器基础上,选定合适的模型结构,通过某种自监督学习任务,逼迫Transformer从大量无标注的自由文本中学习语言知识。这些语言知识以模型参数的方式,存储在Transformer结构中,以供下游任务使用。
从 RoBERTa 学到的
- 增大预训练数据量,能够有效改善模型表现。
- 延长预训练时间,或增加预训练步数,能够明显改善模型效果。
- 大幅度放大 Batch Size,能够改善模型效果。
模型结构
同样使用 Transformer,采用不同模型结构,效果也不同。
Encoder-AE 结构
单 Transformer,双向语言模型。
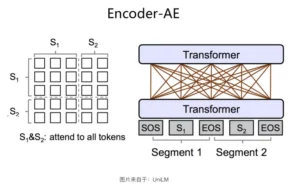
输入句中的未被Mask的任意单词两两可见,但是被Mask掉的单词之间都相互独立,互不可见。在预测某个被Mask掉的单词的时候,所有其它被Mask的单词都不起作用,但是句内未被Mask掉的所有单词,都可以参与当前单词的预测。
从对比实验的结果来看,适合于语言理解类任务,而在生成类任务上表现不佳。
Decoder-AR 结构
单 Transformer,单向语言模型,典型如 GPT 1、2、3。
相对来说适合做生成而不是理解,因为单向结构看不到下文。
Encoder-Decoder 结构
两层 Transformer,一层为双向(Encoder),负责编码输入信息;一层为单向(Decoder),负责生成单词。
这里的 Decoder 侧除了可以看到之前生成的单词,还能看到 Encoder 侧的所有输入单词 。而这一般是通过 Decoder 侧对 Encoder 侧单词,进行 Attention 操作方式来实现的,这种 Attention 一般放在 Encoder 顶层 Transformer Block 的输出上。
在进行预训练的时候,Encoder 和 Decoder 会同时对不同 Mask 部分进行预测:Encoder 侧双向语言模型生成被随机 Mask 掉的部分单词;Decoder 侧单向语言模型从左到右生成被 Mask 掉的一部分连续片断。两个任务联合训练,这样 Encoder 和 Decoder 两侧都可以得到比较充分地训练。
该结构在理解类和生成类任务上表现都很好,但因为有两层 Transformer,参数量随之增加,较为“笨重”。其效果一定程度上也归功于参数量的增加。
Prefix LM
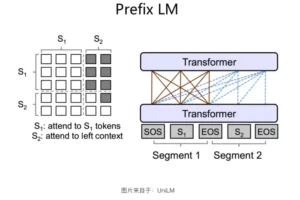
这是一种 Encoder-Decoder 结构的变体。它使用单 Transformer,前半部分作为 Encoder,后半部分作为 Decoder。这种分割占用是通过在 Transformer 内部使用 Attention Mask 来实现的。
实践表明,这种结构在语言理解任务上的表现弱于标准的 Encoder-Decoder。有可能是因为参数量规模的差异。此外,在Decoder侧,Transformer的每层 Block对Encoder做Attention的时候,标准的Encoder-Decoder模式,Attention是建立在Encoder侧的最后输出上,这样可以获得更全面完整的全局整合信息;而Prefix LM这种结构,Decoder侧的每层Transformer对Encoder侧的Attention,是建立在Encoder的对应层上的,因为这种模式的Encoder和Decoder分割了同一个Transformer结构,Attention只能在对应层内的单词之间进行,很难低层跨高层。
在生成类任务上,该结构与标准 Encoder-Decoder 表现差异不大。
Permuted Language Model(PLM)
模型效果为什么好?
归结于几个因素:
- 更高质量、更多数量的预训练数据。(高质量的数据越多,包含知识越多)
- 增加模型容量及复杂度。(参数量)
- 更充分地训练模型。(Batch Size)
- 有难度的预训练任务。
- 对于单词级的 Mask 语言模型来说,Span 类的预训练任务效果最好。所谓 Span 类的任务,就是 Mask 掉的不是一个独立的单词,而是一个连续的单词片断,要求模型正确预测片断内的所有单词。Span 类任务,只是一个统称,它会有一些衍生的变体,比如 N-Gram,就是 Span 模型的一个变体,再比如 Mask 掉的不是单词而是短语,本质上也是 Span 类任务的变体,这里我们统称为 Span 类任务。
- 对于句子级的任务,NSP 任务学习两个句子是否连续句:正例由两个连续句子构成,负例则随机选择一句跟在前一句之后,要求模型预测两者是否连续句子。本质上,NSP 在预测两个句子是否表达相近主题,而这个任务,相对 MLM 来说,过于简单了,导致模型学不到什么知识。ALBERT 采用了句子顺序预测 SOP (Sentence Order Prediction):跟 NSP 一样,两个连续出现的句子作为正例,但是在构造负例的时候,则交换句子正确顺序,要求模型预测两个句子出现顺序是否正确,这样增加任务难度,StructBERT 也采取了类似的做法。实验证明 SOP 是有效的句子级预测任务。
就是说,Transformer结构本身,目前并非制约预训练模型效果的瓶颈,我们可以仅仅通过增加高质量数据、增加模型复杂度配以更充分地模型训练,就仍然能够极大幅度地提升Bert的性能。
这说明了什么呢?这说明了大数据+大模型的暴力美学,这条粗暴简洁但有效的路子,还远远没有走到尽头,还有很大的潜力可挖。尽管这带来的副作用是:好的预训练模型,训练成本会非常高,这不是每个研究者都能够承受的。
其他知识的引入
显式知识(结构化)
两种思路:学习结构化知识;将结构化知识和文本融合。
理论上,结构化知识是蕴含在这些文本内的,因为我们的外部知识库也是通过技术手段从自由文本里挖掘出来的。如果我们的预训练数据量特别大,且使用的特征抽取器能力特别强,实际就不太需要单独再把结构化知识独立补充给Bert这类预训练模型,预训练模型应该能够直接从自由文本中就学会这些知识。
另一方面,对于数据比较少的专业领域知识而言,单独补充还是很有必要的。
多模态预训练
学习不同模态间知识的映射关系。需要使用模态间的对齐数据做训练,成本较文本数据来讲要高出很多。对于“文本-图片”类的训练来说,我们需要联合学习三种模型:文本模型、图片模型以及文本和图片之间的语义对齐预训练模型。从模型结构来说,目前主流结构有两种:双流交互模型和单流交互模型。
双流交互模型
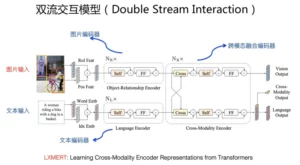
一般文本预训练目标和标准的Bert做法类似,通过随机Mask一部分文本单词的语言模型来做;图片预训练目标类似,可以Mask掉图片中包含的部分物品,要求模型正确预测物品类别或者预测物品Embedding编码;为了能够让两个模态语义对齐,一般还要学习一个跨模态目标,常规做法是将对齐语料中的“文本-图片”作为正例,随机选择部分图片或者文本作为负例,来要求模型正确做二分类问题,通过这种方式逼迫模型学习两种模态间的对齐关系。典型的双流模型包括LXMERT、ViLBERT等。
单流交互模型
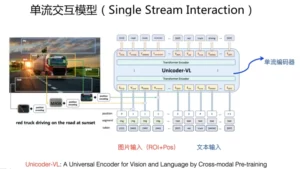
输入的图片,经过上述的Faster-RCNN物体识别和位置编码后,和文本单词拼接,整体作为Transformer模型的输入。也就是说,单流模型靠单个Transformer,同时学习文本内部单词交互、图片中包含物体之间大的交互,以及文本-图片之间的细粒度语义单元之间的交互信息。单流模型的预训练目标,与双流交互模型是类似的,往往也需要联合学习文本预训练、图片预训练以及对齐预训练三个目标。典型的单流模型包括Unicoder-VL、VisualBERT、VL-VERT、UNITER等。
不管是增大预训练数据量的需求,还是更多模态联合训练的需求,都要求“数据先行”。
从两阶段模型到四阶段模型
对于专业领域,两阶段模型有时表现也不太好,而预训练阶段很难兼顾所有领域,因此,可以考虑更多的“预训练”。
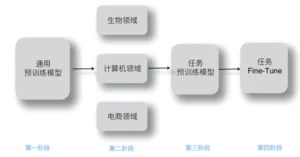
通用预训练 - 领域预训练 - 任务预训练 - 任务Fine-tuning
领域预训练阶段,可能会面临因为参数调整导致的“灾难遗忘”问题,即一些通用语言知识被冲掉。

Comments NOTHING