
原文:深度学习中的注意力模型
注意力机制的“起源”——人类的视觉注意力机制,优先将有限的注意力分配到更需要关注的地方,以快速获取更多有用的信息。
为什么要注意力?
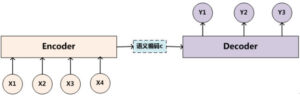
在传统模型中,基于一个输入,构造中间语义向量,以此生成后续输出,那么输入中的每一个词对于后续输出的每一个词的贡献是一样的。举例而言,在机器翻译中,输入的英文句子中每一个词,对于翻译出的中文句子中的每一个词,有着相同的贡献,这显然不符合常理。在句子较短时,这种影响还不明显,而一旦文本很长时,中间语义向量相比原文本,一定会丢失许多有价值的信息,因此我们需要注意力机制来“聚焦”。
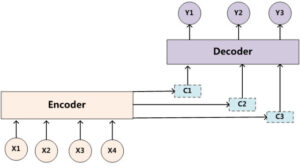
由于输入中的不同单词对输出中的不同单词的贡献不同,就应当有一个衡量指标,可以将其视作一个概率分布值,表示了对当前输出词,注意力机制分配给输入中每一个词的注意力大小。
如何计算注意力分配概率?
对于采用 RNN 的 Decoder 来说,对于 $i$ 时刻来说,我们使用函数 $F(hj, H{i-1})$ 来计算对 $h_j$ 对应单词的注意力分配概率,即以 Decoder 中上一个隐层,和该输入单词对应的隐层作为输入,从而输出一个值。$F$ 函数在不同论文中有不同选择。
Attention 机制的本质思想
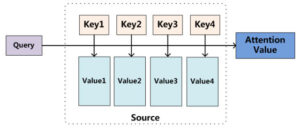
对 $Q$ 和每一个 $K$ 计算相似性,乘以 $V$,最后求和,就得到了 $Q$ 和 $Source$ 之间的 Attention 值。其本质就是一个 $Q$ 对 $Source$ 中的 $Value$ 加权求和的过程。
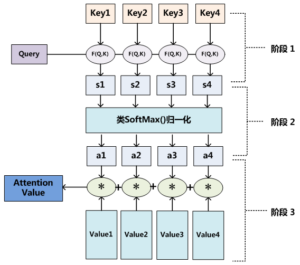
具体可分为:
- 利用函数 $F$ 计算 $Q$ 和 $K$ 的“相似度”
- 将相似度归一化或 SoftMax为概率(系数)
- 对 $V$ 加权求和
对于 $F$ 函数,最常见的方法包括:求两者的向量点积、求两者的向量 Cosine 相似性或者通过再引入额外的神经网络来求值

Self Attention 模型
Self Attention 是 $Source=Target$ 的一种特殊情况。
好处:
- 能够捕获文本中长距离的依赖特征
- 对于增加计算的并行性有一定帮助

Comments NOTHING