
Training a RNN Language Model
At each step, the model have the prefix and predict what’s the next word. We don’t use what the model suggested but penalize the model for not having the correct word and then go with what’s actually in the corpus and ask it to predict again. So the model don’t predict the whole sentence but do prediction step by step. The “recurrent” happened by using the output from prediction of last position and something else as the input of current position.
Obviously, it’s more effective to split the whole corpus into sentences or documents and use algorithm like stochastic gradient descent which allow us to compute a loss or gradients for a small chunk of data and update. Furthermore, we usually process a batch of sentences (may be 32 sentences) with similar length, compute loss and gradients and update weights.
Trainning the parameters of RNNs: Backpropagation for RNNs
The derivative of $J^{t}(\theta)$ w.r.t the repeated weight matrix $\bold{W}_h$ is:
$$
\frac{\partial J^{t}(\theta)}{\partial \bold{W}h} = \sum{i = 1}^{t} \frac{\partial J^{t}(\theta)}{\partial \bold{W}h} | {(i)}
$$
That means the gradient w.r.t the repeated weight is the sum of gradient w.r.t each time it appears. Be attention that the $\bold{W}_h$ is different every time it appears.
Proof with multivariable chain rule
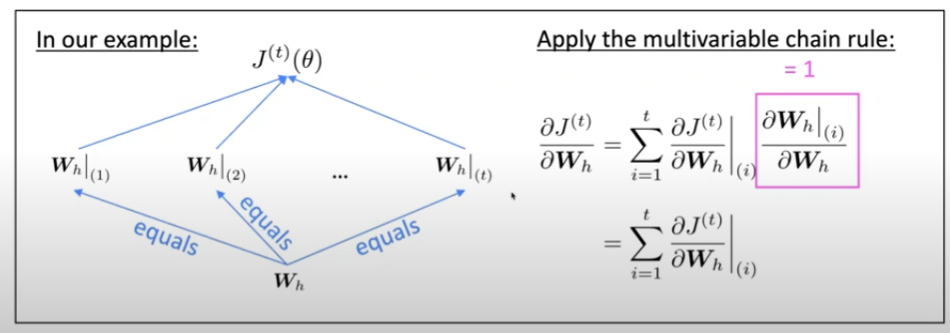
Backpropagation for RNNs
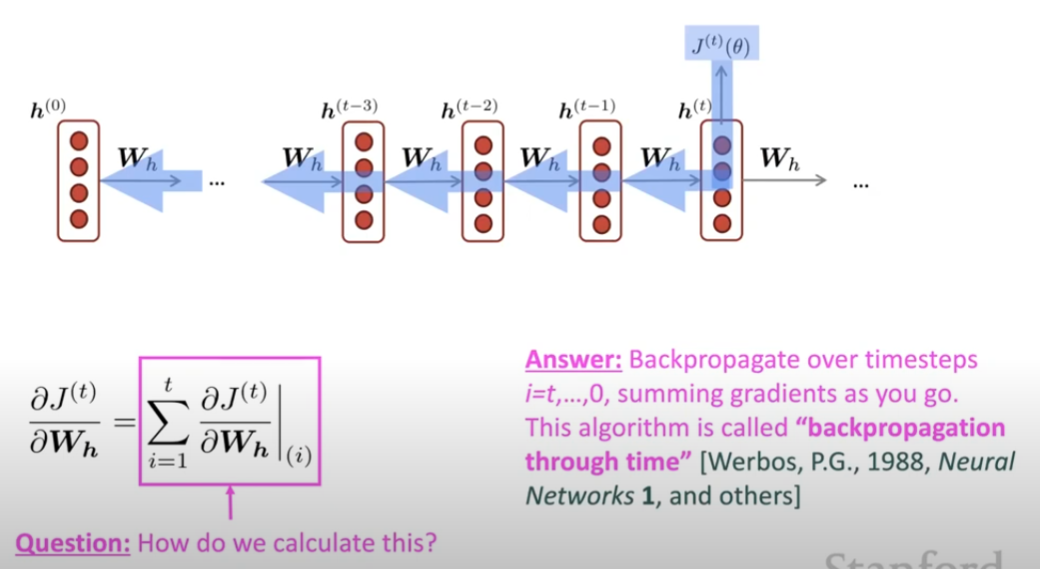
In practice, we usually don’t sum up all the gradients. What we do, called truncated backpropagation, is summing up a fixed time steps like 20. That’s the thing we use to update the weight matrix.
Generate text with RNN Language model
It’s easy to start with a beginning word. We can also generate with nothing (using a special token as the first token). Then we get a distribution for words that could be the next word. How we end is as well as having a beginning of sequence special symble, we have and end of sequence special symble. As long as the RNN generate the end of sequence symble, we finish the task.
Compared with n-gram model (lecture 5), RNN perfomes better.
Evaluation of Language model
The standard method is called perplexity. The definition is shown below:

Obviously, we prefer low perplexity. There is a simple explaination for it. Suppose we have a perplexity of 53, that means our uncertenty of the next word equals to that of tossing a 53-dimension dice and it coming up as 1.
Why we care language model?
It’s a subcomponent of many NLP task, especially those involving generating text or estimating the probability of text.
Recap
Language Model: A system that predicts the next word.
Recurrent Neural network: A family of neural networks that:
- Take sequential input of any length
- Apply the same weights on each step
- Can optionally produce output on each step
They are different things.
Other RNN uses
- sequence tagging: part-of-speech tagging (entity recognition)
- sentence classification: sentiment classification
- language encoder module: question answering
- generate text: speech recognition, machine translation, summarization
Problems with Vanishing and Exploding Gradients
Vanishing
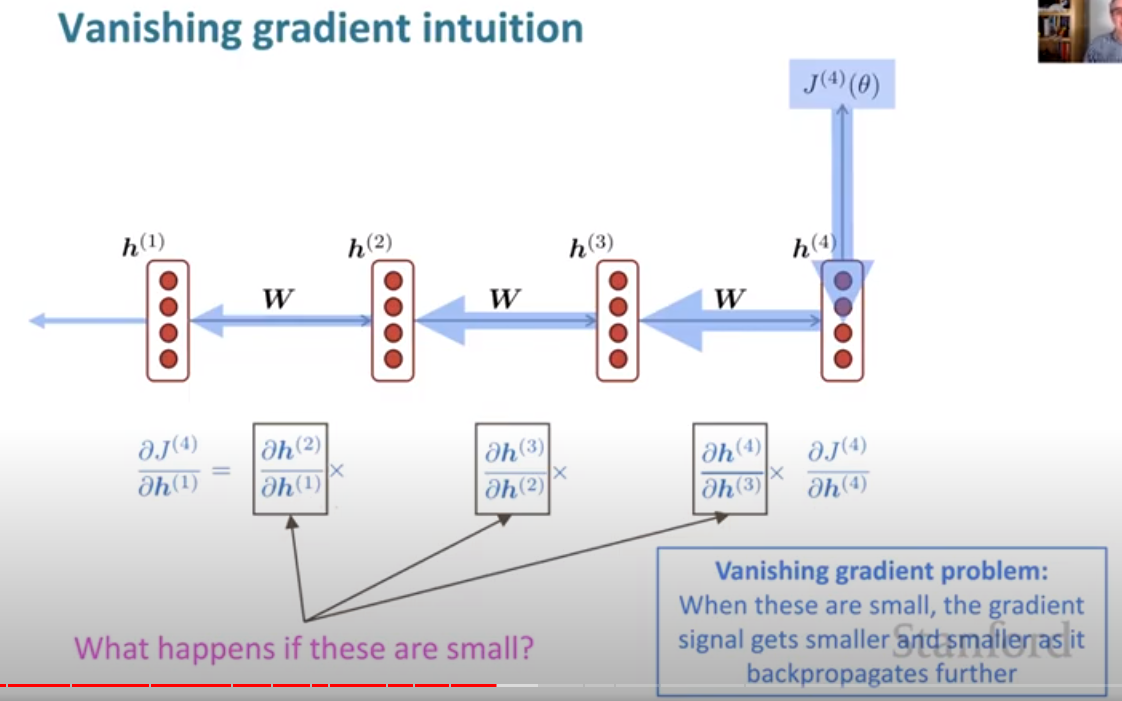

When $\bold{W}_h$ is small, and $l$ is large, the exponential value would be smaller and even vanish.
The vanishing gradient is a problem because it makes our model good at modeling nearby effects (normal gradient) but bad at long-term effect (vanishing gradient). For example, the word we predict at the end of a sentence will not be affected by the beginning word.
How to fix vanishing gradients
A RNN with seperate memory. Long Short-Term Memory RNNs.
Exploding
A too large update of parameter is obviouse a problem. In the worsest case, we may get a Inf or Nan result.
Gradient clipping: Solution to exploding
If the norm of the grediant is greater than the threshold we configured, we simply just scale it down. We still go along the same direction but a smaller step.
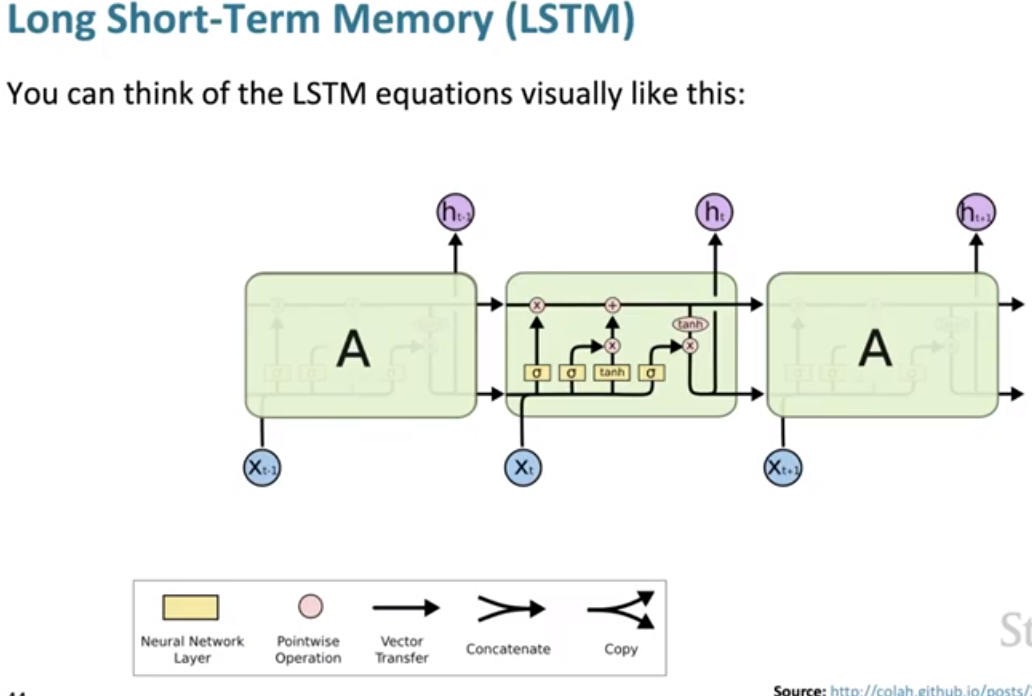
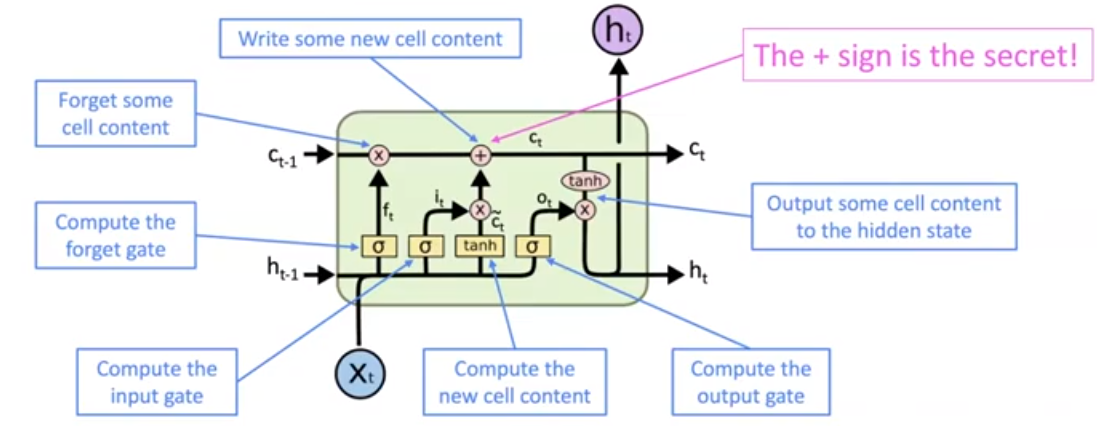
Long Short-Term Memory RNNs (LSTMs)
We preserve some information from previous time steps and some of the current content, combine them as our new content.
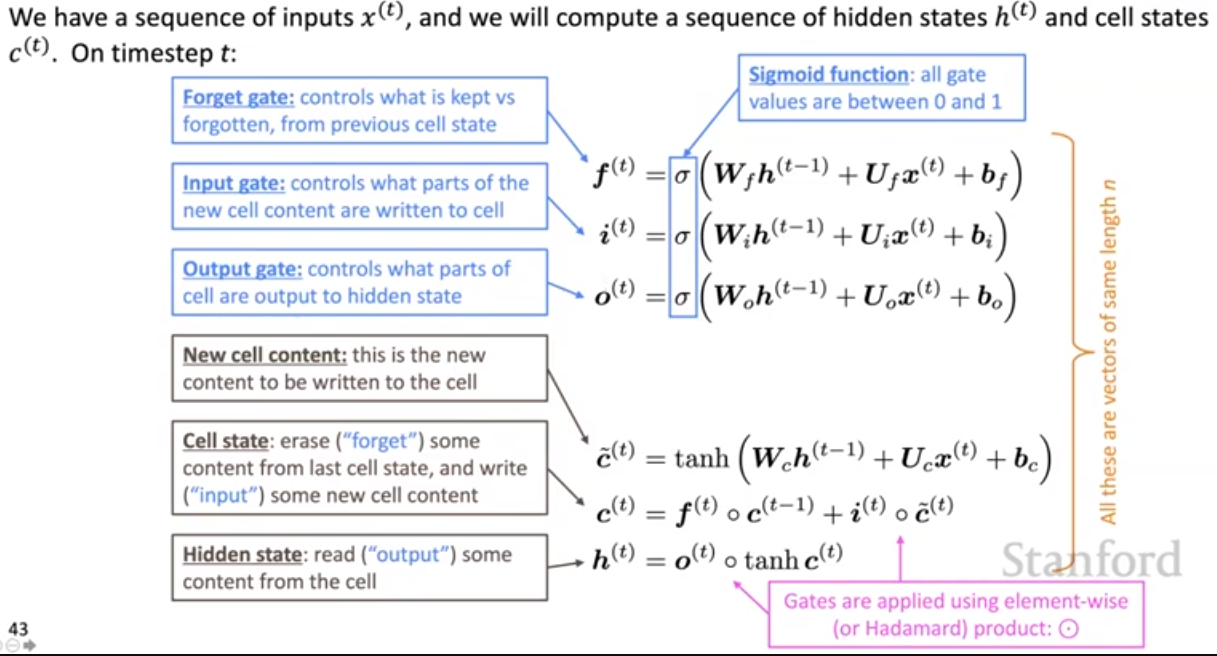
Some of the function can be calculated in parallel.

Comments NOTHING