
For language which there isn’t much parallel data available, commonly the biggest place where you can get parallel data is from Bible translations.
Statistical Machine Translation
Alignment
Alignment is the correspondence between particular words in the sentence pair. It can be many-to-one, one-to-many , many-to-many or some words just have no counterparts.
It’s a latent variable, processing it requires special algorithm.
Break down further
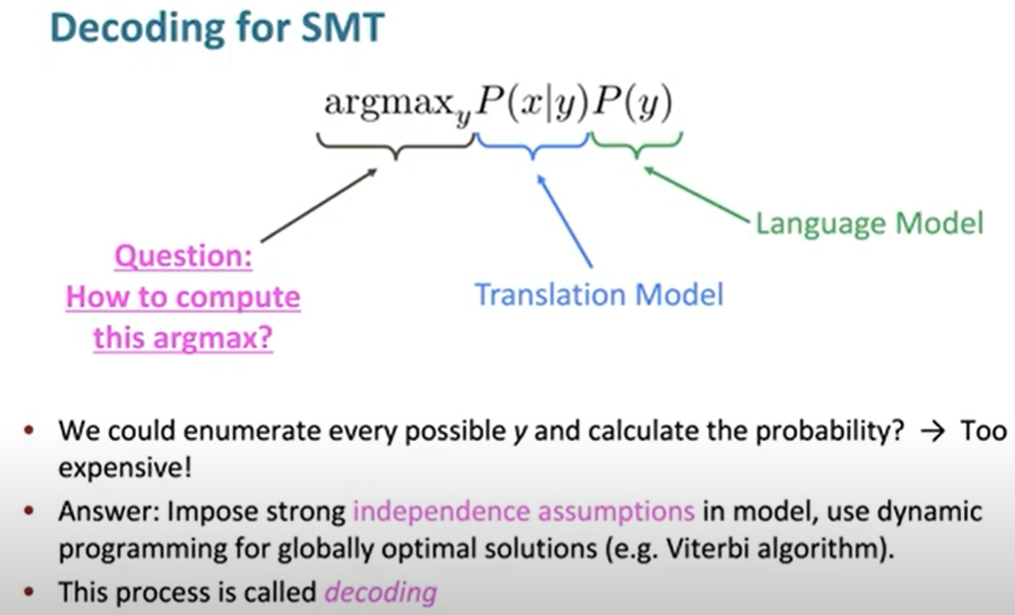
Enumerating every $y$ will have an exponencial cost of sentence length. We just do thing like we have done in language model, predict words one by one.
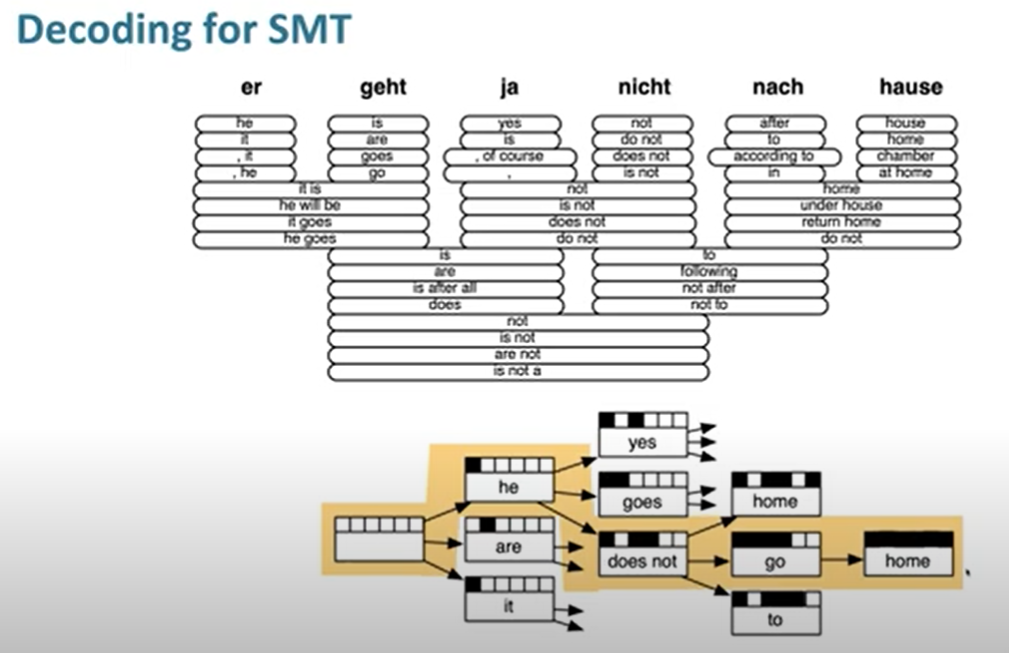
Order makes sense in translation. We can first translate words (phraeses) from source to target language and take them as LEGAO to generate a sentence.
Neural Machine Translation, Seq2Seq
A way to do MT with a single (large) end-to-end neural network.
Common consists of two neural networks (RNNs), one for encode and another for decode. Encoding of the source sentence (final hidden state) provides initial hidden state for decoder RNN.
Decode RNN is a language model to generate target sentence, conditioned on encoding.
There is a picture showing what our model does in the test time:
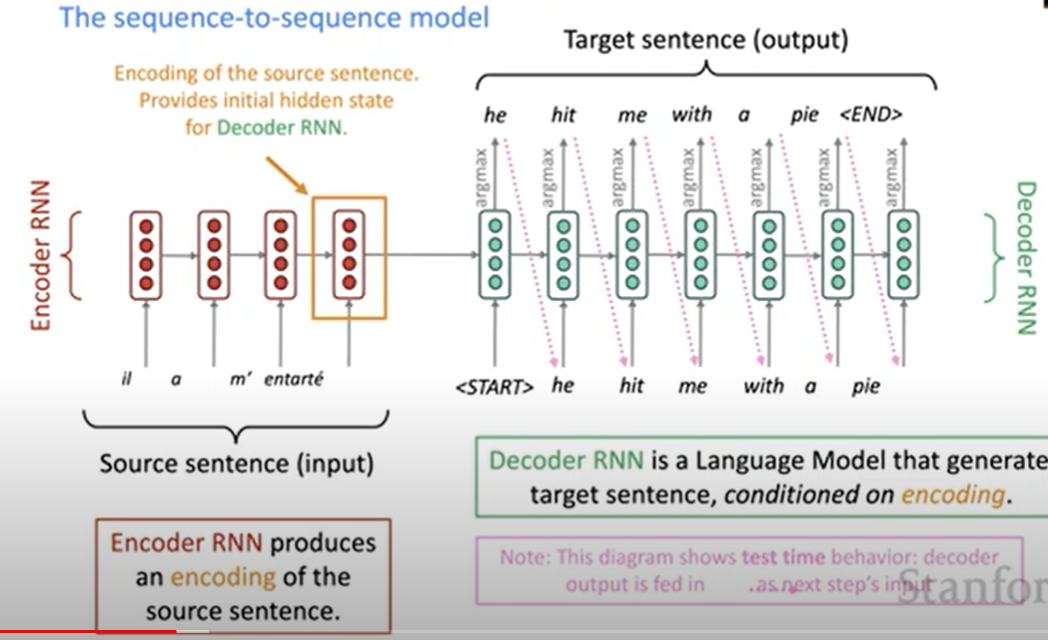
In the training time, encode process stay the same, and what we do in the decode part is just the same to previous language model (given words and generate next word, teacher forcing).
Seq2Seq can do something else
- Summarization (long text to short text)
- Dialogue
- Parsing (transition based, what we do previously)
- Code generation (natural language to python code)
For each word, not only the previous word but also the source sentence determine the next word. So the plexity of this model could be very low like 4 or even 2.5.
Trainning
First we get a big parallel corpus.
With batches data of source and target sentences, we feed them to the ecoder LSTM and feed its final hidden state as the initial state of decoder LSTM. For each position, we have an actual word, predicted word and a loss. With the total loss, we make use of gradient descent as usual.
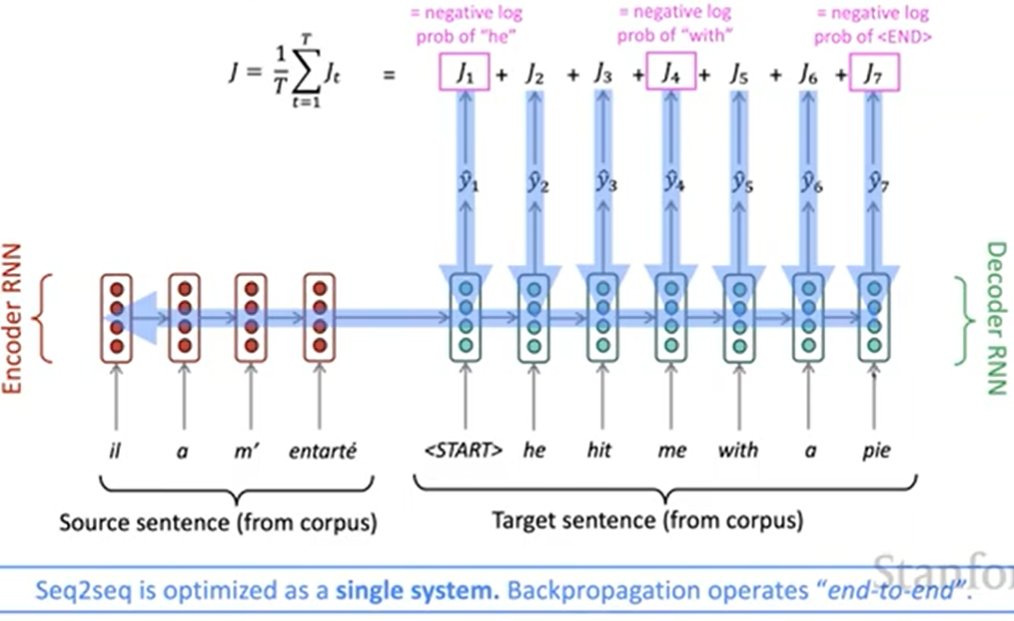
Pay attention to that we backpropagate (update) through not only the decoder part but also the encoder part. That why we call the model a single system which operates “end-to-end”.
Muti-layer RNNs
Simple RNNs have been “deep” on one dimension (they unroll over multi time steps), but we can also make them “deep” in another dimension by apply multiple RNNs.
This allow the network to compute more complex representations. The lower RNNs should compute lower-level features and the higher RNNs should compute higher-level features.
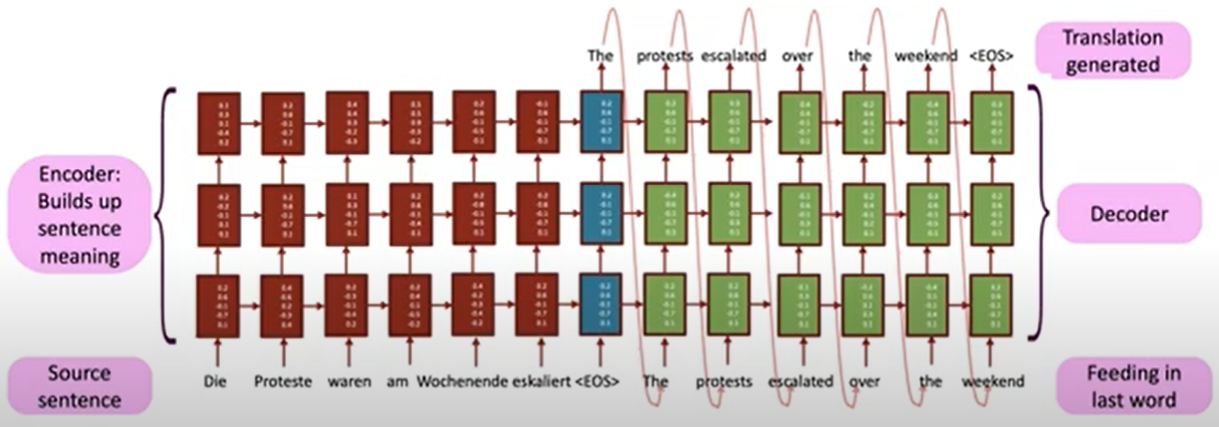
Greedy decoding
In the decode process, we take current predicted word which has the highest probability as part of input of next step. So we call this as greedy decoding (highest probability).
Problem: No way to undo decisions.
Exhaustive search decoding
Find the sentence that maximize probability. We could try to comupting all possiable sequences. But this is too expensive.
Beam search
Choose a beam size k, and keep track of the k most probable partial translations (called hypotheses) at each step. Beam search cann’t gurrantee to get optimal result, but it’s still more effcient. In somewords, we just keep the most possiable k words in current step and go on. At each step, we keep k most possiable routes from all routes and abdon others. Repeat it until the end.
Stopping criterion:
In greedy decoding, we stop until it generate a
In beam search decoding, we just place the routes with
Problem: longer hypotheses have lower scores, so it prefer to generate longer sentences.
Fix: Normalize by length. Divide the score function previously showed with the sentence length.
Evaluation of Machine Translation
BLEU (Bilingual Evaluation Understudy): compute the human translations and machine translation to compute a similarity score based on n-gram precision and plus a penalty for too-short system translations. It’s useful but imperfect.
Attention
Seq2Seq: the bottleneck problem
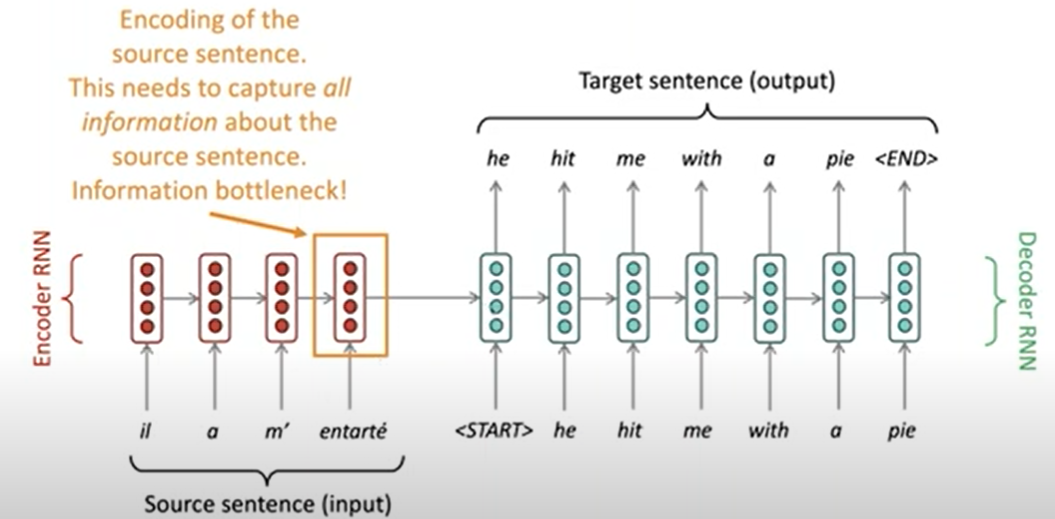
Attention provides a solution to the bottleneck problem.
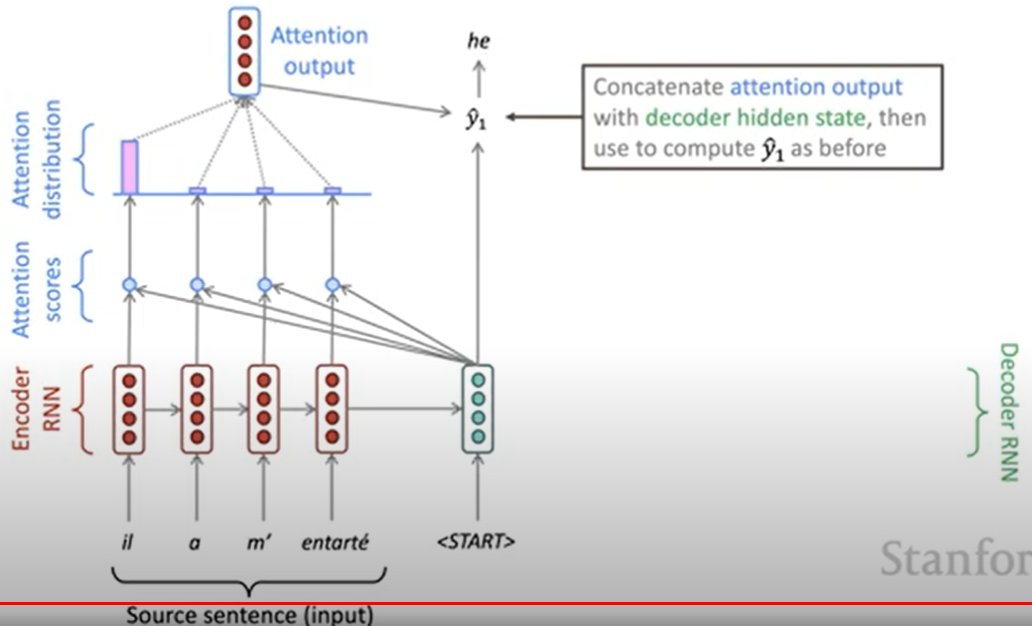
Core idea: on each step of the decoder, use direct connection to the encoder to focus on a particular part of the source sequence.

Comments NOTHING