
Issues with RNN models
- Linear interaction distance: words that should interacte with each other have a linear distance between them.
- Lack of parallelizability: Forward and backward passes have $O(n)$ unparallelizable operations. But GPUs can perform a bunch of independent computations at once.
Word window

We can stack more layers to get more contexts, but there are always some finite fild.
Attention
Let’s see attention within a single sentence.

The computation between attention layers is unparallelizable. But within the same layer, it can be done in parallel.
Self-Attention

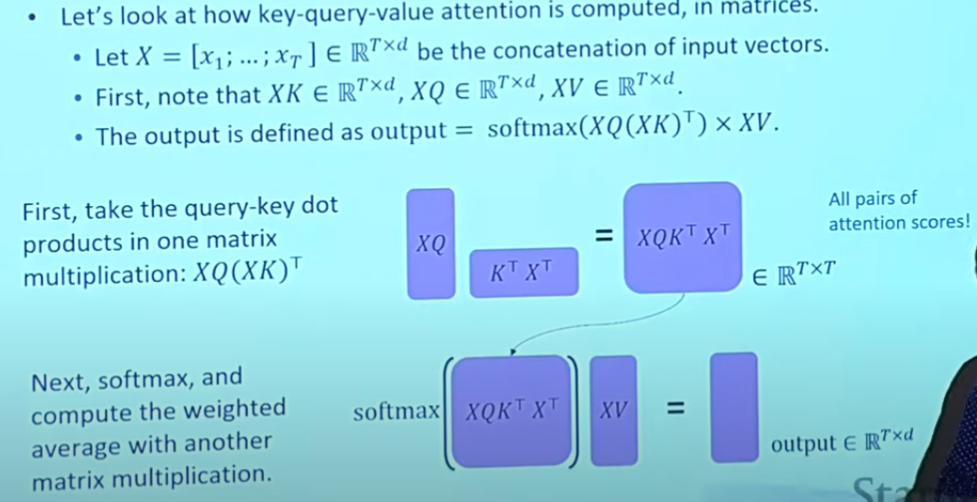
A simple explaination: for every word embedding $a$, we use all words information to produce a weighted embedding $b$, which now contain not only information of the original word but also other words. Naturally, the original word is the dominant ingredient.
Just as the equation showed, we use $k$ and $q$ to produce the weight, and with value we get the final product.

Problem 1: Sequnce Order
Self-Attention doesn’t build in order information, we need to encode the order of sentence in our keys, quries and values.
We can represent each sequence index as a vector $p_i$. And for the new $v_i$, $q_i$, $k_i$ we use now, we just add $p_i$ on each of the old (original) version them. It’s ok to concatenate them. But usually we just add them.
There are several ways to build $p_i$
- Position representation vectors through sinusoids
- Position representation vectors learned from scratch
Problem 2: No nonlinearities for DL
It’s all just weighted average.
There is an easy fix: add a feed-forward network to post-process each output vector. The FF network processes the result attention.
Problem 3: Need to ensure we don’t “look at the future” when predicting a sequence
Fix: masking the future in self-attention (we do this for all decoder layers, not just the first layer)
To use self-attention in decoders, we need to ensure we cant’t peek at the future (or the prediction is useless).
To enable parallelization, we mask out attention to future words by setting attention scores to $-\infin$.
When we calculate the attention scores, only the words before the current word could have a normal scores. For all words after the current word, the score is just $-\infin$.
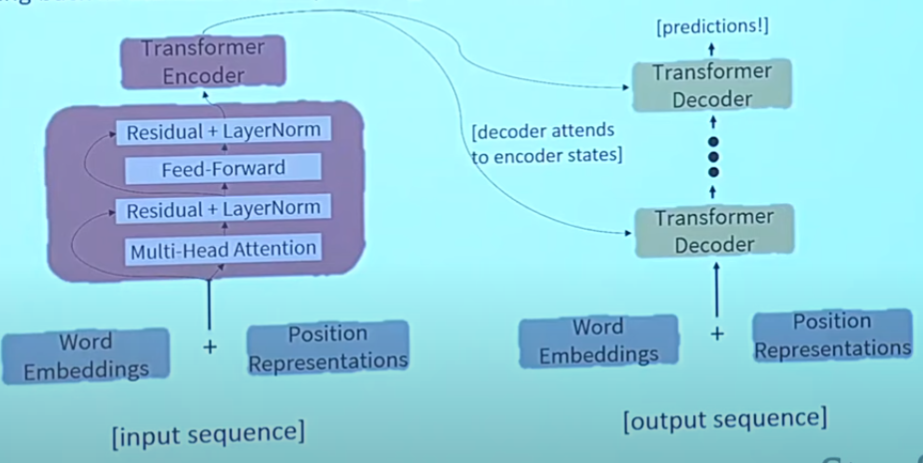
The Transformaer Encoder-Decoder
Key-Query-Value Attention

Multi-headed Attention
For words $i$, self-attention “looks” where the attention score is high. We need some ways to focus on dofferent position for different reasons.


Residual Connections

Layer Normalization

Scaled Dot Product

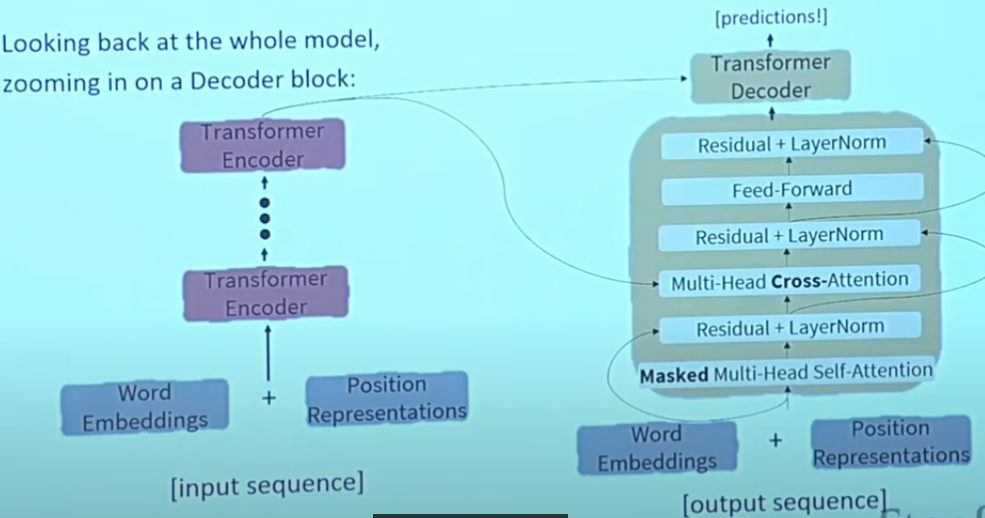
Cross Attention (details)
Could think as the same operation but different source of inputs.


Problems
- Quadratic compute in self-attention: Comuputing all pairs of interactions means our computation grow quadratically with the sequence length.
- Position representation

Comments NOTHING