
Machine Translation
将源语言翻译成目标语言,是早期人工智能的经典应用之一。
早期的MT
1950s,早期的机器翻译是rule-based的,需要使用字典。这种思路后被认为不可能成功。
Statistical MT
1990s-2010s,基于统计方法的机器翻译。其核心理念是从数据中构建、训练一个基于概率的模型,通过给定的源语言,我们希望得到: $ argmax_y P(y|x) $ 。这一步显然不太容易。但通过Bayes Rule,我们可以等价的求: $ argmax_y P(x|y)P(y)$ 。 虽然前半部的条件概率与之前没有太大不同,但是后半部分 $ P(y) $ ,表示着一个句子是正常的英语语句的概率。显然,前者需要人工的标注来说明两种语言的语句的对应关系,而我们使用的数据集中,显然有大量已经是正常英语语句的材料,不需要人工标注,这样训练出来的模型准确性很高,可以很好地提高翻译质量。
另一方面,我们还需要大量 $x$ 对应 $y$ 的并行语料。
我们可以进一步分解,现在要考虑: $ P(x,a|y) $ 。
其中 $a$ 是 alignment ,也就是单词级别的对应关系(两种语言间)。这种对应关系,可能是一对一,一对多,多对一,甚至可能是多对多的。此外,也要考虑到单词顺序等。这种复杂的关系使得alignment建模非常困难。
另一方面,我们最终要求的是使得概率最大的 $y$ ,显然,为了得到它,我们需要去枚举所有可能的 $y$ ,这一操作的消耗是巨大的。
为了解决这一问题,在搜索的早期,我们会把一些概率较低的选择直接舍弃掉。
举个例子:
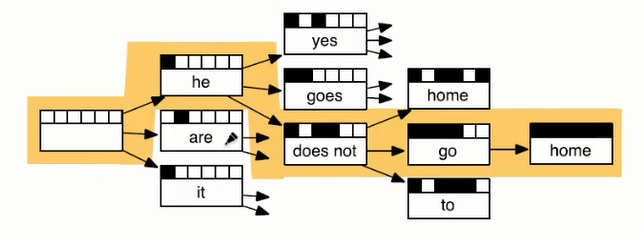
我们执行一个容量为3的搜索,在第一步,我们舍弃了当前概率较低的两个选择,只保留了“he”,而后每一步也如此。(更进一步的内容可以搜索参考“beam search”)
SMT的系统非常复杂,实现细节繁多。
Neural MT
使用单个神经网络进行机器翻译。
神经网络用于解决机器翻译的框架叫做 sequence-to-sequence ,用到两个循环神经网络(RNN),如下图所示:
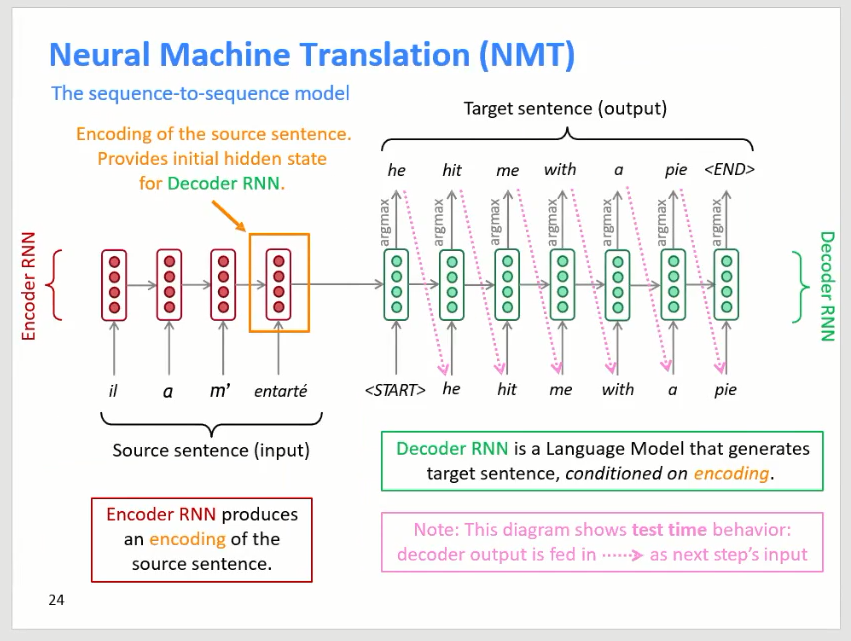
左侧为Encode RNN网络,用于将输入的语句(源语言)进行编码,例如编码为一个500维的向量。对语句中每一个词都做Embeding,由关于上一个单词的和关于当前单词的输入,形成当前的向量,最终得到包含有整个语句信息压缩的500维向量。
右侧为Decode RNN网络,用于解码之前编码好的向量,翻译为目标语言,每一步翻译一个单词。解码过程实际上是一个分类过程,类别个数与我们的词表大小一致。
此外,由于是将语句编码为固定维数变量,其中可能有信息的损失。
对seq2seq模型的优化——attention
现在我们希望上一节中提到的500维向量,能够捕捉到原句子中的所有语义信息(比如单词顺序)。因为如果在翻译过程中,只关注当前单词,那么原句的一些信息会有损失。为了避免这种情况,我们根据当前的500维信息,看向原句的每一个单词,并对其相关性做一个评估,得到每一个权重(alignment分数),乘以每个单词对应的500维向量,做一个加权和。这样得到的信息,不仅包含当前单词,而且有其他单词的信息。
我们记 $\alpha_{ij}$ 为在解码第 $j$ 个单词时,原语句第 $i$ 个单词的权重,它说明了Decode过程中 $R_j$ 与 $Ri$ 的接近程度。(两者均为向量)
$$
\alpha{ij}=cos(R_i,R_j)
$$
attention技术改善了模型表现,解决了信息瓶颈问题,减少了梯度消失问题,也提供了一些可解释性(alignment)。
Comments NOTHING