
本文翻译自博主 Sam 的文章—— Hashing。
部分内容的翻译使用了 ChatGPT 和微软翻译。All content in this post is translated from Sam's article: Hashing. Please click the link to read it.
Some content is translated with the help from ChatGPT and Microsoft Translation.
作为一个程序员,你每天都要使用哈希函数。哈希函数在数据库中被用来优化查询;在数据结构中被用来加速一些操作;在安全领域被用来保证数据安全。你与科技的每一次交互,几乎都与哈希函数有关。
哈希函数是很基础的,任何地方都有它们的身影。
但是,哈希函数的具体定义是什么?它们如何工作呢?
在这篇文章中,我们要揭开哈希函数的神秘面纱。我们会从一个简单的哈希函数开始,然后学习如何测试一个哈希函数的好坏,最后分析真实世界中对哈希函数的一种应用——哈希映射。
什么是哈希函数?
哈希函数是这样一种函数:它接收输入,一般是字符串,然后输出一个数字。如果你用同样的输入多次调用哈希函数,你总会得到同一个数字,并且函数返回的数字总在一定的区间(不论输入如何)。具体的区间取决于哈希函数本身,可能是 32 位整数(对应 0 到 40 亿),也可能更大。
如果我们用 JavaScript 写一个伪哈希函数,它可以长这样:
function hash(input) {
return 0;
}即便你不知道哈希函数是如何使用的,上面这个函数也显然是无用的。接下来让我们看看如何评价一个哈希函数的好坏,之后深入了解哈希映射中是如何使用哈希函数的。
什么样的哈希函数是好的哈希函数?
由于输入可以是任意字符串,但返回的数字必须在某个确定的区间内,因此两个不同的输入可能会返回同一个数字。这被称为“哈希碰撞”,而好的哈希函数,就是要最小化可能产生的碰撞。
显然,我们不可能完全消除碰撞。如果我们写一个返回值在 0 到 7 之间的哈希函数,并给它 9 个互不相同的输入,则至少会产生一个碰撞。
hash("to") == 3
hash("the") == 2
hash("café") == 0
hash("de") == 6
hash("versailles") == 4
hash("for") == 5
hash("coffee") == 0
hash("we") == 7
hash("had") == 1上面是某个对 8 取余的哈希函数的输出。不论传入的 9 个值是什么,它总会输出 8 个互不相同的数字中的一个,所以碰撞不可避免。我们的目标是尽可能地减少碰撞。
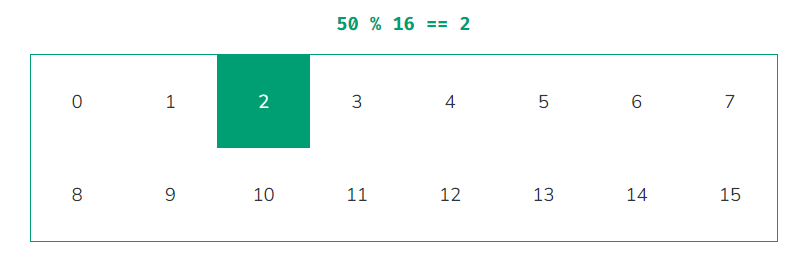
上图是一个例子,不论输入的数字是多少,对 16 取余后,总能在 16 个格子中找到一个位置。
接下来,每当我们输入一个值,得到哈希函数的输出,我们就将对应格子的颜色变深一些。这是一个简单且直观的观察哈希函数避免碰撞的能力的方法。我们追求的是一个美观且平滑的分布。如果一个哈希函数产生的图案有太多的成簇的深色格子,我们就知道这个哈希函数不够好。
Haskie:你说过,当一个哈希函数对两个不同的输入输出相同的值时,这就是碰撞。但是如果我们有一个将输出映射到大范围内的哈希函数,并将它们映射到一个小网格上,我们会不会在网格上创建许多实际上并不是碰撞的碰撞呢?在我们的 8x2 网格上,数字 1 和 17 都映射到第二个方格中。
这是一个很好的观察。你说得完全正确,我们在网格上会创建“伪碰撞”。不过,没关系,因为如果哈希函数很好,我们仍然会看到均匀的分布。将每个方格的值增加 100 与将每个方格的值增加 1 一样好。如果我们有一个糟糕的哈希函数导致很多碰撞,那将会很明显。我们很快就会看到这一点。
下面我们将 1000 个随机生成的字符串映射到一个更大的网格中。

这些值的分布十分均匀,因为我们使用了一个好的,著名的哈希函数——murmur3。这个哈希函数在真实世界中被广泛运用,因为它不仅能产生均匀的分布,计算也十分高效。
如果我们使用一个糟糕的哈希函数,网格将会是什么样的?
function hash(input) {
let hash = 0;
for (let c of input) {
hash += c.charCodeAt(0);
}
return hash % 1000000;
}这个哈希函数遍历给定字符串中的每一个字符,并将它们对应的数值累加。最后使用模运算(%)保证最终值处于 0 到 1,000,000 之间。我们不妨将这个哈希函数称为 stringSum。
这是它产生的分布(输入是 1000 个随机生成的字符串):

这个分布看起来与 murmur3 产生的分布十分不同,是什么导致的?
问题在于给定的字符串是随机生成的。让我们来看看如果输入并非随机生成,而是处于 1 到 1,000 之间的所有整数(字符串),两个哈希函数产生的分布会有什么不同:


现在问题更清晰了。当输入不是随机生成的时候,stringSum 的分布形成了某种模式。而 murmur3 的分布,与随机生成的输入没什么不同。
如果我们将最常用的 1000 个英语单词哈希化:


虽然更细微,但我们确实在 stringSum 的分布中看出了某种模式。而 murmur3 的分布依然像之前一样。
这就是好的哈希函数的力量:不管输入如何,输出总是均匀分布。接下来我们再讨论一种可视化方法,然后聊聊为什么好的哈希函数很重要。
雪崩效应
另一种评估哈希函数的方法被称为“雪崩效应”。它指的是当输入中的一个比特改变时,输出中有多少个比特改变了。如果一个哈希函数具有好的雪崩效应,那么应当在输入中的单个比特翻转时,输出中平均有 50% 的比特翻转。
正是这个特性使得哈希函数能够避免在分布中形成模式。如果输入中小改变只能引起输出中的小改变,就容易形成模式。模式意味着不好的分布,以及更多的碰撞。
下面我们以一个 8 比特二进制数为例,来可视化雪崩效应。上面的数字是输入,下面的数字是 murmur3 的输出,绿色的数字表示输出中翻转的比特,红色的数字表示未翻转。
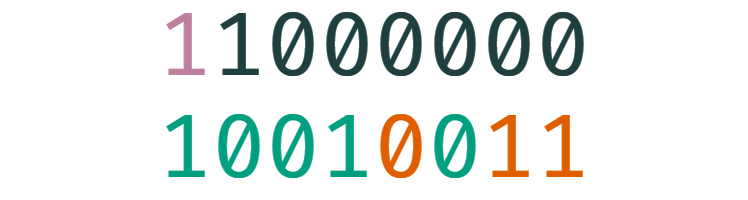
murmur3 的表现很好,虽然有时候翻转的比特位不足 50%,但平均来说已经达到了。
让我们看看 stringSum 的表现:
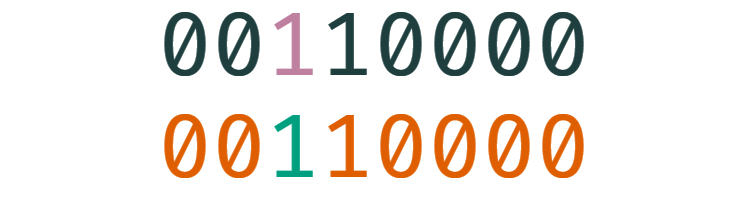
显然是很糟糕的。输入中翻转一个比特位时,输出中也只有一个比特位翻转。
这些为什么重要
我们已经学习了一些评价哈希函数好坏的方法,但我们还没有讨论这些为什么重要。让我们以哈希映射为例。
为了理解哈希映射,我们先讲讲什么是映射。映射是一种数据结构,它允许你存储键值对。这是一个 JavaScript 的例子:
let map = new Map();
map.set("hello", "world");
console.log(map.get("hello"));这里我们将一个键值对("hello" → "world")存储到映射中。然后将键“hello”对应的值打印,也就是“world”。
一个更有趣的现实世界中的例子是找异构词。异构词是指由相同字母组成的不同单词。例如 antlers 和 rentals,或者 article和 recital。如果你有一个由单词组成的列表,并且想找到所有异构词,你可以分别将每个单词内的字母排序,然后将其作为一个映射中的键。
let words = [
"antlers",
"rentals",
"sternal",
"article",
"recital",
"flamboyant",
]
let map = new Map();
for (let word of words) {
let key = word
.split('')
.sort()
.join('');
if (!map.has(key)) {
map.set(key, []);
}
map.get(key).push(word);
}这段代码将产生如下映射:
{
"aelnrst": [
"antlers",
"rentals",
"sternal"
],
"aceilrt": [
"article",
"recital"
],
"aabflmnoty": [
"flamboyant"
]
}实现一个简单的哈希映射
哈希映射是映射的众多实现中的一种,并且实现哈希映射也有很多方法。我们将展示一种最简单的方法,使用一个由列表组成的列表。在现实世界中,内部的列表一般被称为“桶”。哈希函数被用在键上,以决定用哪一个桶来存储键值对,然后将键值对放入该桶中。
让我们逐步来实现一个简单的 JavaScript 哈希映射。我们将从底层开始,先了解一些实用方法,然后再实现 set 和 get 方法。
class HashMap {
constructor() {
this.bs = [[], [], []];
}
}我们从创建 HashMap 类开始,它带有一个 constructor 方法,用于初始化三个桶
class HashMap {
// ...
bucket(key) {
let h = murmur3(key);
return this.bs[
h % this.bs.length
];
}
}bucket 方法使用 murmur3 来决定给定的键使用哪个桶。这是我们的哈希映射中唯一一个使用哈希函数的地方。
class HashMap {
// ...
entry(bucket, key) {
for (let e of bucket) {
if (e.key === key) {
return e;
}
}
return null;
}
}entry 方法以 bucket 和 key 作为参数,扫描给定的桶,并返回含有给定键的条目,如果不存在,则返回 null。
class HashMap {
// ...
set(key, value) {
let b = this.bucket(key);
let e = this.entry(b, key);
if (e) {
e.value = value;
return;
}
b.push({ key, value });
}
}set 方法接受一个键值对,并将其存储在我们的哈希映射中。它通过使用我们之前创建的 bucket 和 entry 方法来实现。如果找到了已有的条目,其值将被覆盖。如果没有找到已有的条目,键值对将被添加到映射中。在 JavaScript 中,{ key, value } 是 { key: key, value: value } 的简写形式。
class HashMap {
// ...
get(key) {
let b = this.bucket(key);
let e = this.entry(b, key);
if (e) {
return e.value;
}
return null;
}
}get 方法类似于 set 方法。它使用 bucket 方法和 entry 方法找到 key 关联的条目,就像 set 方法做的那样。如果条目存在,就将其对应值返回。如果条目不存在,则返回 null。
代码稍微有点多。你需要理解的是,我们的哈希映射是一个列表的列表,哈希函数被用于决定使用哪个列表来存储和读取给定的键。
下图是一个示例:
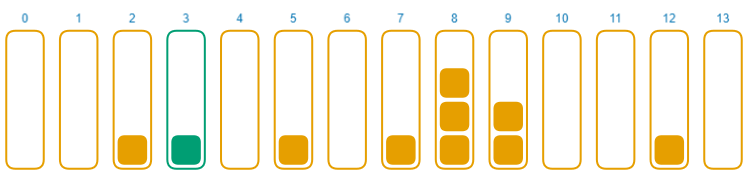
由于我们使用 murmur3 作为哈希函数,桶间的分布应当是十分均匀的。虽然有时候会有不平衡,但通常是比较均匀的。
为了从哈希映射中读取一个值,我们要先将键哈希化,以决定从哪个桶中读取值。然后在该桶内所有的键中找到给定的键。
正是通过哈希化,我们将这个搜索步骤最小化,这也是为什么 murmur3 被优化用于提高速度。哈希函数越快,我们找到正确的桶进行搜索的速度就越快,整体上我们的哈希映射也就越快。
这也是为什么减少碰撞是十分重要的。如果我们使用文章开头的哈希函数(总是返回 0),我们将会把所有键值对存储在第一个桶中。寻找任意键意味着要检查哈希映射中的所有值。使用一个具有良好分布的哈希函数,我们将搜索成本降低到 1/N,N 代表桶的数目。
让我们看看 stringSum 的效果:
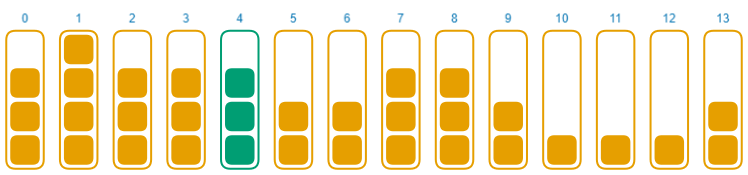
有趣的是,好像这个分布也不错。虽然也能注意到一些模式,但整体来说还可以。
Haskie:终于!stringSum 胜利了。我就知道它总会派上用场的。
不要这么急,Haskie。我们需要谈论一个严重的问题。在这些连续的数字上,分布看起来还不错,但我们已经看到 stringSum 没有良好的雪崩效应。这不会有好结果。
真实世界中的碰撞
让我们来看看两个真实世界中的数据:IP 地址和英语单词。我们将会使用 100,000,000 个随机 IP 地址,以及 466,550 个英文单词,分别使用 murmur3 和 stringSum 将它们哈希化,并看看有多少碰撞产生。
IP 地址:
| murmur3 | stringSum | |
|---|---|---|
| 碰撞总数 | 1,156,959 | 99,999,566 |
| 占比 | 1.157% | 99.999% |
英文单词:
| murmur3 | stringSum | |
|---|---|---|
| 碰撞总数 | 25 | 464,220 |
| 占比 | 0.005% | 99.5% |
当我们在现实世界使用哈希映射,我们通常不是用它们存储随机值。我们可以想象,在服务器的限速代码中计算我们已经遇到某个 IP 地址的次数。或者在整个历史上统计书中单词出现的次数,以追踪它们的来源和流行程度。stringSum 对于这些应用来说效果很差,因为它的碰撞率非常高。
人为碰撞
现在是一些关于 murmur3 的坏消息。我们不仅需要担心由于输入的相似性导致的碰撞问题。看看这个例子。
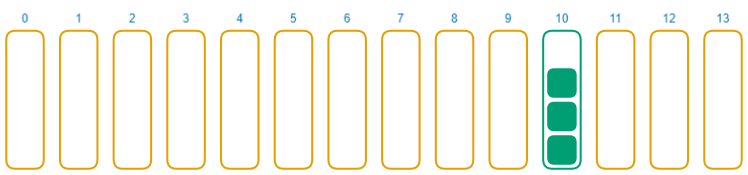
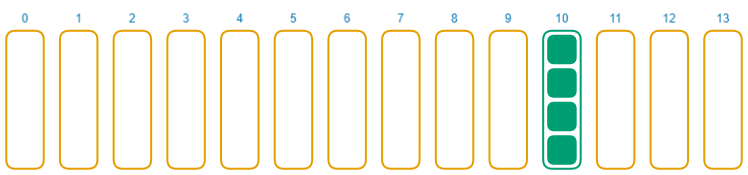
发生了什么?为什么这些乱七八糟的字符会被映射成同一个数字?
我使用 murmur3 将 141 兆个随机字符串哈希化,来找到那些被 murmur3 映射为数字 1228476406 的值。哈希函数对特定的输入总是返回同样的输出,所有使用暴力法找到碰撞是可行的。
Haskie:对不起,141 兆?就像……141 后面跟着 12 个 0?
是的,这花了我 25 分钟。计算机是很快的。
如果你的软件使用用户输入构建哈希映射,那么恶意行为者能够轻易地获得碰撞,这可能会带来灾难性的后果。以 HTTP 标头为例。一个 HTTP 请求像这个样子:
GET / HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: google.com你不用看懂所有东西,只要知道第一行是请求的路径,以及剩余行是标头。标头是键值对,所以 HTTP 服务器倾向于使用映射去存储它们。我们可以传递任何我们想传递的标头,因此我们可以恶意地传递一些我们明知道会导致碰撞的标头。这会显著降低服务器的运行速度。
这并不仅仅是理论上的。如果你搜索“哈希 DoS”,你将会发现许多这类例子。2000 年代中期就存在大量此类事件。
有许多方法缓解 HTTP 服务器的压力,比如忽略乱七八糟的标头键,限制存储的标头数量。但是现代哈希函数,如 murmur3 提供了更通用的解决方案:随机化。
在前面的部分,我们展示了一些哈希函数的实现。这些实现使用了单个参数:input。现代的许多哈希函数会使用第二个参数:seed,有时候也叫 salt。在 murmur 中,这个 seed 是一个数字。
目前为止,我们都用 0 作为种子,让我们来看看如果使用 1 作为种子,会有怎样的变化。
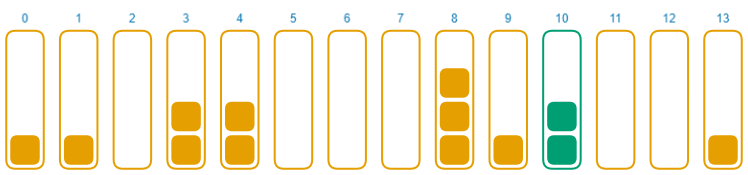
就像这样,从 0 到 1,碰撞问题消失了。这就是种子的作用:它以不可预测的方式使哈希函数的输出随机化。它是如何实现的超出了本文的范围,所有的哈希函数都会以自己的方式实现这一点。
对于相同的输入,哈希函数仍然返回相同的输出,只不过输出是输入和种子的组合。在使用一个种子时发生的碰撞,在使用另一个种子时不应当再发生。编程语言通常会在程序启动时生成随机数字作为种子,所以你每次运行你的程序时,种子都不一样。作为一个坏人,在不知道种子的情况下,就无法造成损害了。
如果你仔细观察上面的可视化图和之前的图,哈希函数的输入是相同的,但它们产生了不同的哈希值。这意味着,如果你用一个种子来哈希一个值,并希望在将来能够对比它,你需要确保使用相同的种子。
对于使用哈希映射的情况来说,不同种子产生不同的值并不会影响效果,因为哈希映射只在程序运行期间存在。只要在程序的整个生命周期中使用相同的种子,你的哈希映射将继续正常工作。如果你在程序之外存储了哈希值,比如存入文件中,你需要小心确保知道使用了哪个种子。
Playground
作为一个传统,我为你制作了一个 playground 来编写你自己的哈希函数,并在网格中可视化它们的效果。点击这里来尝试下吧!
结论
我们已经知道了什么是哈希函数,学习了一些评价哈希函数好坏的方法,了解了当哈希函数不够好时会引发的问题,以及一些别有用心的人会如何利用哈希函数搞破坏。
哈希函数的世界非常广阔,在这篇文章中我们只是触及了表面。我们还没有讨论过加密哈希与非加密哈希的区别,我们只涉及了成千上万种哈希函数用途中的其中一种,而且我们还没有详细讨论现代哈希函数的实际工作原理。
如果你真的对这个话题非常感兴趣,并希望学习更多,那么下面是一些推荐阅读:
- https://github.com/rurban/smhasher 这个仓库包含了测试哈希函数好坏的黄金标准。它对大量的哈希函数进行了各种测试,并将结果呈现在一个大表格中。虽然其中的所有测试内容可能有些难以理解,但这就是哈希测试的最新技术发展所在。
- https://djhworld.github.io/hyperloglog/ 这是一个关于名为 HyperLogLog 的数据结构的交互式介绍。它被用于高效地计算非常大的集合中唯一元素的数量。它运用了哈希的方法,以非常巧妙的方式完成计数任务。
- https://www.gnu.org/software/gperf/ 当给定所需哈希的预期元素集合时,这个程序能够自动生成一个“完美”的哈希函数。
快来加入 Hacker News 上的讨论吧!
Acknowledgements
感谢每一个阅读了本文早期草稿,以及提供了宝贵意见的人:
以及每一个帮助我找到 murmur3 哈希碰撞的人:
Patreon
经过 Load Banlancing 和 Memory Allocation 的成功,我已经决定开设一个 Patreon 主页:https://patreon.com/samwho 。在接下来的所有文章中,我将发布一篇仅供 Patreon 支持者查看的幕后文章,其中将讨论每篇文章的决策、困难和所学到的经验。这将让你深入了解这些文章的发展过程,我对为这篇文章撰写的幕后文章感到非常兴奋。
如果你喜欢我的写作,并希望继续支持,我会非常感激你成为我的 Patreon 赞助者。❤️

Comments NOTHING