
简单记录下这次任务中的一些心得
关于并行
DDP 只做了数据并行,而 FSDP 有不同策略,可以在数据并行之外,做到优化器、梯度和模型参数分片(full_shard、shard_grad_op)。但是,模型参数并行会使得训练速度减慢,在参数量较大时是不可接受的。
据一位朋友分享,30B 参数的模型,训练数据差不多 200w,模型并行的话差不多要训练 3 年。
关于降低资源占用
比较可行的方案,是使用 LoRA(即 Low-Rank Adaption),根据实际训练情况,选择性地使用 fp32、fp16、int8、int4,以降低显存占用。
需要注意,这种方案会固定模型参数,然后引入一些额外参数来进行训练,原模型参数是不变的,之后使用时,要在加载原模型后加载 LoRA 参数。
关于显存占用
以前一直以为训练时显存占用的大头是模型参数本身,现在才知道大头是优化器,见下图:
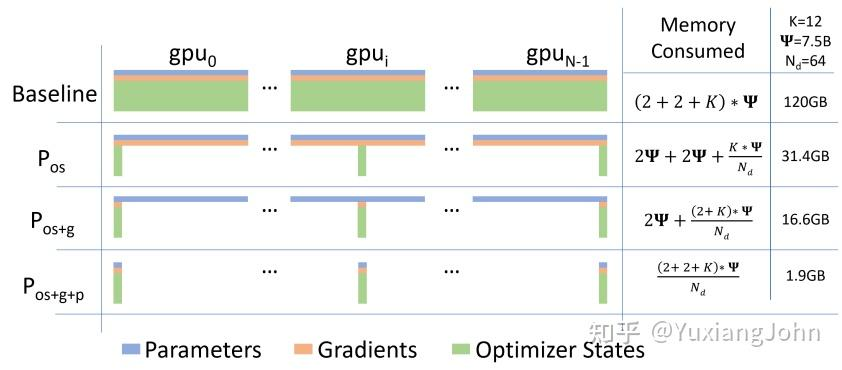
关于 FSDP 的模型并行
之前以为用 FSDP 实现模型并行,只要写好 Trainer 类,运行命令加入 --fsdp "full_shard" 即可,但实际使用后发现每个 GPU 的占用依然是全参数。
之后发觉,torchrun ----nproc_per_node=8 命令实际上是开了 8 个进程,分别去执行训练脚本,每个脚本有自己的显卡(通过 local_rank),所以还是每个 GPU 加载一个全参数。
此贴 中的楼主跟我遇到的问题几乎一模一样。
关于 batch_size 和训练时间
batch_size 减半不一定会使训练时间加倍,虽然不知道是什么原因,以这次实验为例,训练时间仅从 10h 增加到 13h。
关于 PEFT
Parameter-Efficient Fine-Tuning,有以下几种方案:
- Adapter Tuning:设计了一个 Adapter 结构,将其嵌入 Transformer 中,训练时保持原模型参数不变,只更新 Adapter 部分的参数。
- Prefix Tuning:在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。
- Prompt Tuning:类似 Prefix Tuning,但只在输入层加入 prompt tokens。
- P-Tuning V1:由于 prompt 构造会对下游任务的效果产生很大影响,于考虑将 prompt 转换为可以学习的 Embedding 层。
- P-Tuning V2:加入了更多的可学习参数,同时保证了 Parameter-Efficient。
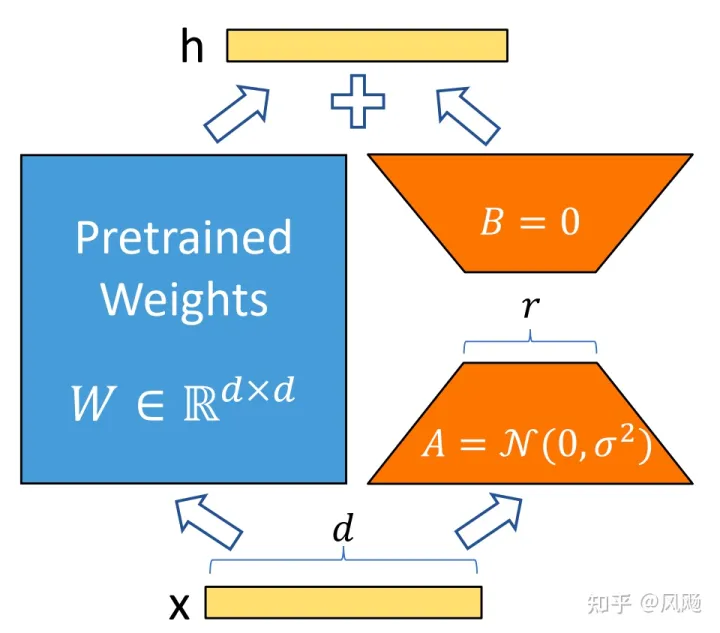
- LoRA:上述方案中,Adapter Tuning 增加了推理延时(因为有额外模型深度),其他方案则减少了可用序列长度(被 prompt 占用)。语言模型参数中,最为关键的是低秩的本质维度(low instrisic dimension),因此在涉及矩阵相乘的模块,引入 A 和 B 两个低秩矩阵模块去模拟 Full-finetune 的过程,相当于只更新低秩本质维度。在推理阶段,直接用训练好的 A 和 B 矩阵参数与原模型参数相加去替换原参数,没有额外计算量,避免了性能损失。

Comments NOTHING